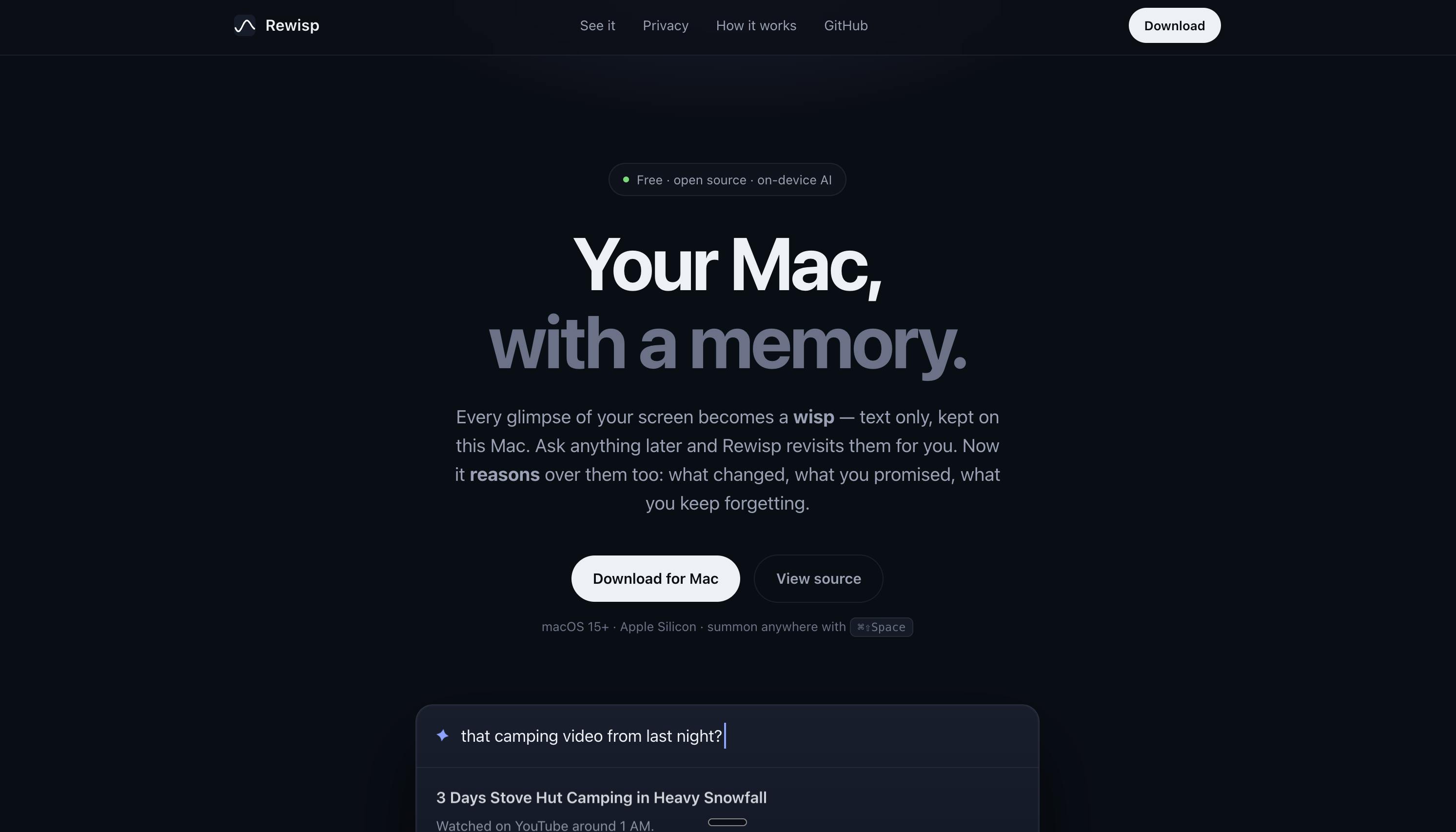
KugelAudio:可自托管的实时文本转语音模型
在 AI 语音合成领域,实时性与隐私保护始终是两大核心痛点。近日,一款名为 KugelAudio 的产品在 Product Hunt 上引发关注,它主打“可自托管的实时文本转语音模型”,为开发者与企业提供了一种兼顾性能与数据控制权的新选择。
核心亮点:自托管与实时性
KugelAudio 最突出的特点在于 自托管(self-host) 能力。这意味着用户可以将模型部署在自己的服务器或本地环境中,无需将文本数据上传至第三方云端服务,从而彻底解决数据外泄风险。对于金融、医疗、法律等对数据隐私要求极高的行业,这一特性尤为重要。
同时,KugelAudio 强调 实时性。在语音合成场景中,低延迟是保证用户体验的关键,尤其是用于虚拟助手、有声读物实时生成、直播配音等场景。虽然具体延迟参数尚未公开,但其定位已明确指向需要快速响应的应用。
技术背景:开源与定制化趋势
KugelAudio 的出现并非孤例。近年来,随着 VITS、Tacotron 等开源 TTS 模型的成熟,自托管语音合成方案逐渐从极客圈子走向商业化。与云端方案(如 Azure Speech、Google Cloud Text-to-Speech)相比,自托管模型允许用户 微调音色、调整语速、优化特定领域的发音,甚至基于少量样本克隆声音。
不过,自托管也意味着更高的技术门槛:用户需要自行管理 GPU 资源(推理通常依赖 GPU)、处理模型优化(如 ONNX 转换、量化)以及维护服务稳定性。KugelAudio 是否提供开箱即用的 Docker 镜像或一键部署脚本,将是其能否降低使用门槛的关键。
潜在应用场景
- 隐私敏感场景:企业内部系统(如客服质检、会议纪要生成)可完全在本地运行,避免敏感语音数据外传。
- 离线环境:车载系统、嵌入式设备等无网络或弱网络环境,自托管模型可保证离线语音合成能力。
- 定制化需求:游戏角色配音、虚拟主播定制音色,创作者可以训练专属模型并本地运行。
行业影响
KugelAudio 的推出,将进一步推动 “AI 语音去中心化” 的进程。当越来越多高质量 TTS 模型能够被个人或中小企业私有化部署,大厂的云服务垄断将面临挑战。不过,与云端方案相比,自托管模型的更新维护需要用户主动参与,如何平衡便利性与控制权,仍是这类产品需要回答的问题。
目前 KugelAudio 尚处于早期阶段,具体支持的语种、声音数量、以及是否提供预训练模型等细节有待披露。对于关注语音合成与数据隐私的开发者而言,值得持续跟踪。